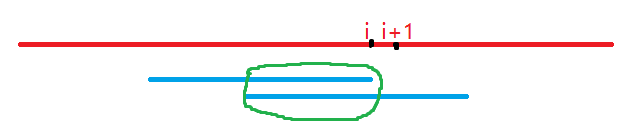
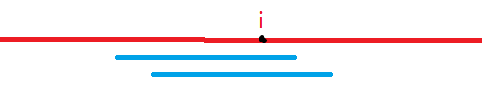
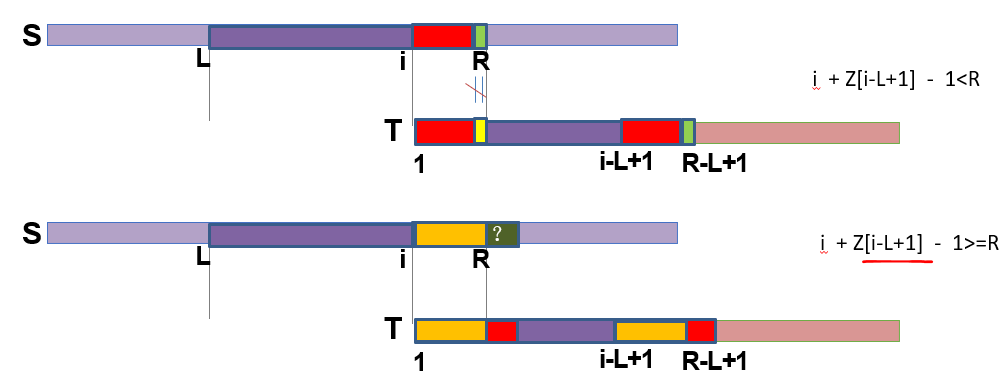
#include<iostream> #include<cstdio> #include<cstring> using namespace std; const int N = 2e7 + 5; typedef long long ll;
char a[N], b[N]; int ex[N], z[N], l1, l2;
void zbox() { int l = 0, r = 0; z[0] = l2; for (int i = 1; i < l2; i++) { if (i > r) z[i] = 0; else z[i] = min(r - i + 1, z[i - l]); while (i + z[i] < l2 && b[i + z[i]] == b[z[i]]) z[i]++; if (i + z[i] - 1 > r) r = i + z[i] - 1, l = i; } }
void exkmp() { int l = 0, r = 0; while (ex[0] < l1 && ex[0] < l2 && a[ex[0]] == b[ex[0]]) ex[0]++; for (int i = 1; i < l1; i++) { if (i > r) ex[i] = 0; else ex[i] = min(r - i + 1, z[i - l]); while (i + ex[i] < l1 && ex[i] < l2 && a[i + ex[i]] == b[ex[i]]) ex[i]++; if (i + ex[i] - 1 > r) r = i + ex[i] - 1, l = i; } }
int main() { scanf("%s%s", &a, &b); l1 = strlen(a), l2 = strlen(b); zbox(); exkmp(); ll ans1 = 0, ans2 = 0; for (int i = 0; i < l2; i++) ans1 ^= (ll)(i + 1) * (z[i] + 1); for (int i = 0; i < l1; i++) ans2 ^= (ll)(i + 1) * (ex[i] + 1); printf("%lld\n%lld", ans1, ans2); return 0; }
AC自动机
KMP保证一个字符串时为线性,那么对于多个字符串,就需要AC自动机了,注意它和自动AC机的区别,它并不能自动AC题目,虽然我以前一直以为它时这个意思. P3808 【模板】AC自动机(简单版)
对于一个字符串,以及一堆长度小于它的模式串,求这个字符串出现了多少个模式串.
例母串为ababa,模式串为a ab aba bc
那么答案为3
AC自动机是KMP与trie树的结合
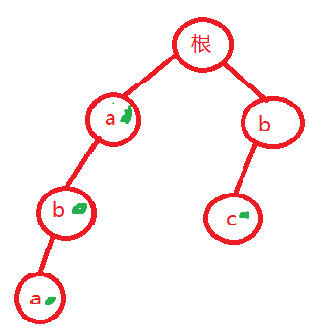
如样例,首先建trie树
其中有绿色标记的代表单词结尾
其思想其实和KMP差不多,只是改成了在树上跳而已
代码
for (int i = 0, j = 0; str[i]; i++) { int t = str[i] - 'a'; while (j && !tr[j][t]) j = net[j]; int p = j; while (p) { ans += cnt[p]; cnt[p] = 0; p = net[p]; } }
这里可以有个优化,就是在建trie图的时候,直接记录到可以跳的位置,那么就可以省掉一层循环
#include<iostream> #include<cstdio> #include<queue> using namespace std;
const int N = 1e6 + 5; int tr[N][26], net[N], cnt[N], idx, q[N], front, tail = -1; char str[N];
void insert() { int p = 0; for (int i = 0; str[i]; i++) { int t = str[i] - 'a'; if (!tr[p][t]) tr[p][t] = ++idx; p = tr[p][t]; } cnt[p]++; }
void build() { for (int i = 0; i < 26; i++) if (tr[0][i]) q[++tail] = tr[0][i]; while (front <= tail) { int t = q[front++]; for (int i = 0; i < 26; i++) { int p = tr[t][i]; if (!p) tr[t][i] = tr[net[t]][i]; else { net[p] = tr[net[t]][i]; q[++tail] = p; } } } }
int main() { int n, ans = 0; scanf("%d", &n); for (int i = 1; i <= n; i++) { scanf("%s", &str); insert(); } build(); scanf("%s", &str); for (int i = 0, j = 0; str[i]; i++) { int t = str[i] - 'a'; j = tr[j][t]; int p = j; while (p) { if (cnt[p] == -1) break; ans += cnt[p]; cnt[p] = -1; p = net[p]; } } printf("%d", ans); return 0; }